FAIR principles
The FAIR principles are a good practice on data sharing in academic communities and beyond. A good starting point for our workshop on data management.
Outside academia there have been similar initiatives to improve data management, which may be more relevant for dedicated communities or scenarios:
In this paragraph we present a number of exercises around the FAIR principles. And we’ll see how the principles work out in the soil domain specifically. FAIR Data is:
Findable
Metadata and data should be easy to find for both humans and computers.
Data and metadata have a unique persistent identifier
- A minimal approach to create a unique identifier (URI) is to combine a local identifier with a domain. For example: https://data.kalro.org/profiles/aa1-49bc-d11e
- In theory, URIs do not need to
resolveto an actual website, but it is a good practice to provide meaningful content at each uri. - Do not use product names and project names in URIs. It will be difficult to maintain persistence.
- Frameworks such as DOI, handle.net and ePIC offer a identification layer for online resources.
For the following datasets, review the uniqueness and persistence of their identifier and the identifier of the data.
- 05b1e57a-8e31-4cdb-aca4-61ae3f21559d
- 10.1016/j.rse.2019.111260
- d5bb6b02-0979-5112-8dd6-9aef6638fb73
- select-nutrition-indicators-data-for-kenya-2022
Perform the same analyses for some datasets on your organisation network.
Describe the data source with rich metadata
Rich metadata includes aspects such as, title, abstract, keywords, who is the author/owner of the resource, when was the resource created, are there any usage constraints, how does the resource relate to other resources.
To evaluate if a tiff-dataset containing texture-clay is relevant to answer your question on soil water availability, which aspects would you expect a metadata description of that dataset to include?
Metadata are searchable in a catalogue
In order to find metadata efficiently, metadata records should be listed in a intuitive search interface
Navigate to the following data portals and search for a dataset on for example soil texture in your area. Note down which aspects you would like to see improved to locate a dataset, or to know when to stop searching, because you assume you have located the best match in the catalogue.
Accessible
Once a user finds the data, it should be clear how they can be accessed.
Metadata and data are retrievable using a standardised communications protocol
Various communities adopted a range of standards for metadata exchange:
Metadata
| Community | Standard | Format/Protocol |
|---|---|---|
| Open data/Sematic web | DCAT | SPARQL |
| Science | Datacite | OAI-PMH |
| Geospatial | iso19115 | CSW/OGC API - Records |
| Earth observation | STAC Catalog | STAC API |
| Search engines | Schema.org | json-ld/microdata |
| Ecology | EML | KNB/GBIF |
A metadata model often is a combination of a schema and a format. Compare the following metadata records, identify which model is used in the record, what differences and communalities do you notice?
Data
Most common in data science is to provide a packaged version of a dataset and deploy it on a repository like Zenodo or Dataverse where it can be downloaded. Zenodo supports Findability and Accessibility of FAIR.
In the spatial and earth observation domain we tend to work with large files and the use of data APIs which allow to request subsets of the data are very common. The Open Geospatial Consortium has defined a number of standards for these APIs, so the APIs themselves are interoperable. The table below shows some of the common APIs. In the first column the older APIs, developed in the 90’s, in the second column their updated representative, recently adopted or still in development.
| Service | OGC API | Description |
|---|---|---|
| Web Map Service (WMS) | Maps | Provides a visualisation of a subset of the data |
| Web Feature Service (WFS) | Features | API to request a subset of the vector features |
| Web Coverage Service (WCS) | Coverages | API to interact with grid sources |
| Sensor Observation Service (SOS) | Sensorthings | Retrieve subsets of sensor observations |
From the Earth Observation domain, an alternative mechanism is increasingly getting adopted. Complete files are stored on a public file repository, by creating an index on the file and enabling range requests, users are able to fetch subsets from the file directly (for which previously, you would have needed a WFS or WCS service).
This mechanism is enabled by new formats such as Cloud Optimised GeoTiff, GeoZarr, and GeoParquet.
Metadata are accessible, even when the data are no longer available
Metadata models usually have a status field, which enables you to indicate that a resource has been archived. The metadata would still be available, so users are aware it once existed.
Interoperable
Data typically are integrated with other data, as well as interoperate with applications or workflows for analysis, storage, and processing.
(Meta)data use a formal, accessible, shared, and broadly applicable language for knowledge representation.
The soil community has a long history of interoperability efforts for soil profile data. Such as:
e-Soter
The e-Soter model has been developed in the e-Soter Research project, based on principles of previous SOil TERrain (SOTER) initiatives. e-Soter is a relational database model, usually implemented as a Microsoft Access database. Some examples of e-Soter implementations:
iso28258:2013
In 2012 various experts in the soil domain grouped around the development of the first formally standardised domain model on soil data, published as ISO28258. ISO28258 adopted the Observations & Measurements conventions of OGC. Each observation on a site, profile, horizon or soil sample is considered an observation. For each observation on a specimen, the measured property and the procedure are captured.
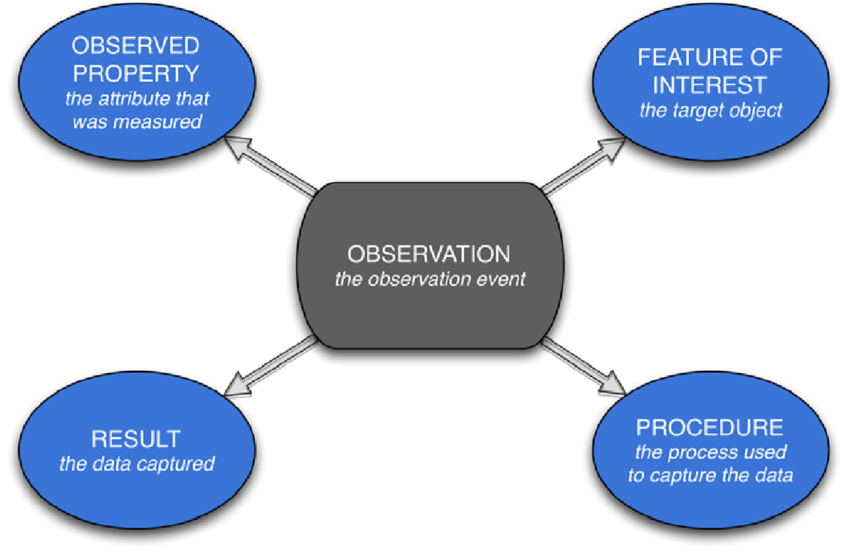
For this exercise we are considering a dataset on observations on soil properties (either field or lab). If you are aware of such a dataset in your organisation or region, use that one, else you can use the KENSOTER dataset. Then answer the following questions:
- Describe the dataset; by region, format, organisation, date, …
- In which column/property are the observed result values stored?
- How is the observation linked to the location and depth of the sample?
- Where is documented the unit used for the value?
- How is documented which soil property is measured
- Where is described which procedure/method has been used for this observation?
- Are metadata about the measurement available, when was the sample analysed, who made the sample, which lab?
Various initiatives adopted ISO28258, and serialised and specialised the model for their community:
- INSPIRE Soil (Europe) and ANZSoilML (Australia) are domain models based on Observations and Measurements, inspired by ISO28258, serialised in GML.
- ISO28258-relational is an implementation of ISO28258 modelled as a relational database.
- Glosis Web Ontology is an evolution of iso28258, using common ontologies from the web, such as semantic sensor network.
Some examples of datasets modelled as INSPIRE Soil:
Download a Soil GML file and try to open it in QGIS. QGIS usually is able to display the profile locations. Alternatively you can use the GML Appschema format in OGR to generate first a SQLite database of the file, before opening it in QGIS.
(Meta)data use vocabularies that follow FAIR principles
A number of common vocabularies are relevant to the soil domain.
The World Reference Base for soil resources provides a framework of code lists on soil and soil classification. These lists are partially published in Agrovoc and partially in Glosis web ontology.
Examine the concept Durisols in agrovoc.
- Notice that the agrovoc page on Durisols looks nicer then the representation linked to its uri. Still it is important to use the persistent identifier when linking to the concept, why?
- Notice that Agrovoc contains many translations for each concept and linkage to wider and narrower terms. These are some of the benefits of linking to a keyword from a common thesaurus.
Metadata include qualified references to other metadata
The context of a dataset gets more clear if you link it to datasets which were used as a source, documents in which it is described, tools with which it has been produced or which tool can be used to view/process it, policies for which it has been created, etc. Consider that users also may traverse the link, to find datasets relevant to a certain policy or tool.
Reusable
Reuse of data is the main goal of FAIR, facilitated by documentation of the data, for different audiences.
Use a clear and accessible data usage license
Users are very interested to know if and how they can use the data. This process is facilitated by adoption of a commonly available license, such as odbl or cc-by, so users (and machines) can identify the applicable license without reading a full document.
Does your organisation provide guidance on which license to use on various data sources? Is it clear when, and when not to use an open license? Are you aware of any data sources which currently do not yet have an assigned data license?
Data are associated with detailed provenance
Provenance is the process of creation and curation of a data source. Which data sources or procedures were used to create the data source. Which processing steps have been applied to the data. What is the lifecycle of the dataset (when will it be archived).
This information is very relevant to potential users of the data, because they can understand if the data has been produced according to their expectations.
In academia provenance and processing are usually described in scientific articles. One can also capture these aspects in a linked metadata record. Some tools (for example ArcGIS and SPSS) create a processing log automatically.
Summary
In this section you learned about the FAIR principles and how this applies to the soil data community. In the next section we will introduce a data management strategy we use on some of our projects. We expect some of the presented tools may be worthwile to have a closer look at, to see if it can support you in your daily tasks.